
W świecie blockchaina i Web3 DID to skrót od decentralized identifier, czyli zdecentralizowanego identyfikatora. To nie jest kolejny login ani modny buzzword, tylko sposób opisywania cyfrowej tożsamości tak, aby użytkownik mógł ją kontrolować bez jednego centralnego pośrednika. W praktyce DID łączy się z portfelem, poświadczalnymi danymi i mechanizmami weryfikacji, które coraz częściej pojawiają się w projektach Web3, fintechu i identyfikacji online.
Najważniejsze rzeczy o DID w skrócie
- DID jest identyfikatorem, a nie pełnym profilem tożsamości.
- Może działać na blockchainie, ale nie musi być od niego uzależniony.
- Największy sens pokazuje dopiero razem z poświadczalnymi danymi i portfelem.
- Model ten daje większą kontrolę nad danymi i lepszą przenoszalność między usługami.
- Największe ryzyka to utrata kluczy, słaba interoperacyjność i zbyt złożone wdrożenie.
Czym jest DID i czym nie jest
W praktyce patrzę na DID jak na cyfrowy uchwyt, którym można wskazać osobę, firmę, urządzenie albo inny zasób, bez uzależniania się od jednego konta w konkretnym serwisie. Sam identyfikator nie musi niczego ujawniać poza tym, że istnieje i że da się go zweryfikować. To ważne rozróżnienie, bo DID nie zastępuje całego systemu tożsamości, tylko stanowi jego techniczny fundament.
Najprościej widać to w porównaniu z klasycznym logowaniem.
| Cecha | Klasyczny login | DID |
|---|---|---|
| Kontrola nad identyfikatorem | Po stronie platformy | Po stronie użytkownika lub jego kontrolera |
| Zależność od pośrednika | Wysoka | Niższa, zależna od metody |
| Przenoszenie między usługami | Często trudne | Zwykle łatwiejsze |
| Zakres ujawnianych danych | Najczęściej szeroki | Można ujawniać tylko potrzebny fragment |
| Weryfikacja | Opiera się na zaufaniu do dostawcy | Opiera się na kryptografii i rozwiązaniu DID |
Największe nieporozumienie polega na tym, że wiele osób traktuje DID jak zamiennik loginu. To zbyt płytkie ujęcie. W rzeczywistości DID jest bardziej jak warstwa adresowania i zaufania, a dopiero na niej buduje się logowanie, poświadczenia i dostęp do usług. Żeby to dobrze ocenić, trzeba zobaczyć, z czego taki identyfikator właściwie się składa.
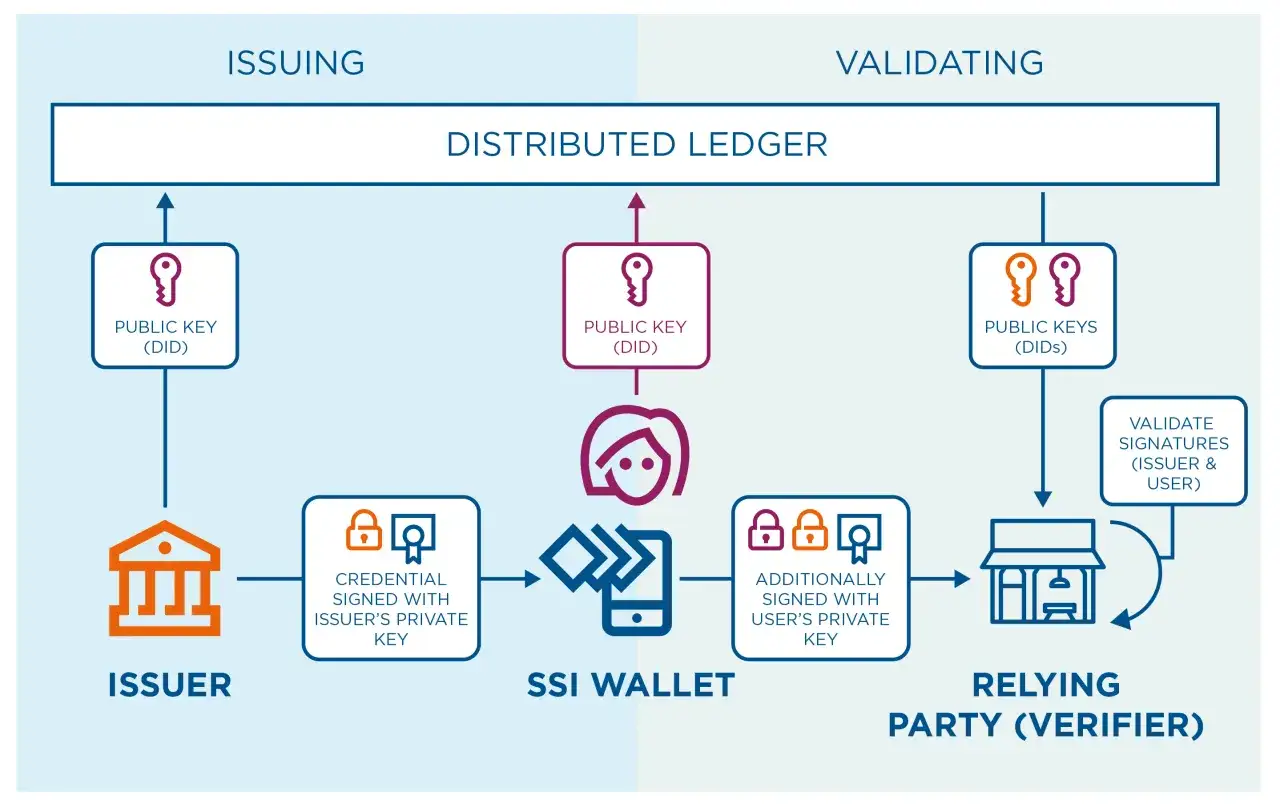
Jak DID działa w praktyce i gdzie wchodzi blockchain
W standardach W3C DID Core 1.0 identyfikator tego typu jest globalnie unikalny i można go rozwiązać do dokumentu DID, czyli zestawu informacji potrzebnych do bezpiecznej interakcji z daną tożsamością. W praktyce nie chodzi więc o sam zapis typu did:method:123, ale o cały mechanizm: identyfikator, dokument, metoda, resolver i reguły aktualizacji. To właśnie ten ekosystem robi różnicę.
Z czego składa się identyfikator
Najczęściej spotkasz zapis w stylu did:metoda:identyfikator. Ten format mówi tylko tyle, że mamy do czynienia z DID i że jego obsługa zależy od konkretnej metody. Sama metoda definiuje, jak taki identyfikator powstaje, jak się go odczytuje, jak można go zaktualizować i kiedy da się go wygasić.
- DID - sam identyfikator, czyli stabilny punkt odniesienia.
- DID document - dokument zawierający klucze, endpointy i inne dane potrzebne do weryfikacji.
- DID method - zestaw reguł dla konkretnego sposobu działania identyfikatora.
- Resolver - komponent, który pobiera aktualny dokument DID.
- Verification material - dane kryptograficzne używane do potwierdzania kontroli.
Po co jest resolver
Resolver to praktyczny pomost między identyfikatorem a światem aplikacji. Gdy system chce sprawdzić, czy dany DID jest aktywny i jakie klucze są z nim powiązane, wykonuje operację rozwiązania. W efekcie dostaje dokument DID oraz metadane, które pozwalają zweryfikować podpis, endpoint lub stan identyfikatora.
To ważne, bo DID nie działa jak zwykły rekord w jednej bazie danych. Można go rozwiązywać do różnych reprezentacji i dla różnych zastosowań, a sama metoda decyduje, jak wygląda odczyt, zapis, aktualizacja i deaktywacja. W praktyce oznacza to, że dwa projekty mogą używać DID, ale technicznie robić to zupełnie inaczej.
Przeczytaj również: Proof of Stake - Jak działa i czy jest bezpieczny?
Dlaczego blockchain jest tylko jedną z opcji
Blockchain bywa używany jako warstwa rejestru, bo daje odporność na pojedynczy punkt awarii i sensowną historię zmian. Ale nie każdy DID musi być oparty na łańcuchu bloków. W zależności od metody można użyć także innych rejestrów, systemów rozproszonych albo mechanizmów, które są poza łańcuchem.To jedna z najbardziej praktycznych rzeczy do zapamiętania: DID nie równa się blockchain. Blockchain może wspierać ten model, ale nie jest jego definicją. Dla projektu Web3 to dobra wiadomość, bo pozwala dobrać architekturę do problemu, a nie wciskać łańcuch tam, gdzie wystarczy prostsze rozwiązanie. Gdy ten mechanizm już działa, łatwiej zrozumieć, czemu wokół DID tak ważne są poświadczenia i portfele.
Portfel, poświadczenia i weryfikacja bez centralnego pośrednika
Sama tożsamość bez dowodów ma ograniczoną wartość. Dlatego DID prawie zawsze pojawia się obok verifiable credentials, czyli poświadczalnych danych, które można sprawdzić kryptograficznie. W modelu W3C VC Data Model 2.0 mamy trzy role, które tworzą cały przepływ: wystawcę, posiadacza i weryfikatora. To właśnie ten układ sprawia, że model ma sens w realnych procesach biznesowych.
| Rola | Co robi | Przykład |
|---|---|---|
| Issuer | Wystawia poświadczenie i je podpisuje | Uczelnia, bank, pracodawca, urząd |
| Holder | Przechowuje poświadczenie w portfelu i pokazuje je wtedy, gdy trzeba | Użytkownik, firma, urządzenie |
| Verifier | Sprawdza autentyczność i aktualność poświadczenia | Platforma, partner biznesowy, aplikacja KYC |
Tu właśnie portfel przestaje być tylko „crypto walletem”. W modelu tożsamości przechowuje nie tylko klucze, ale także poświadczenia i dowody prezentacji. Dzięki temu użytkownik może pokazać wybrany fragment informacji bez oddawania całego zestawu danych. Jeśli ktoś ma udowodnić pełnoletność, nie musi ujawniać całej daty urodzenia. Jeśli potrzebna jest licencja albo dyplom, weryfikator sprawdza podpis i status poświadczenia zamiast prosić o skan dokumentu.
Najbardziej praktyczne zastosowania widzę tam, gdzie jedna instytucja wydaje dane, a wiele usług chce je później weryfikować. To może być KYC używane w kilku serwisach, potwierdzenie członkostwa, licencje zawodowe, dostęp do społeczności albo potwierdzanie kwalifikacji. W takich scenariuszach DID nie jest ozdobą architektoniczną, tylko sposobem na ograniczenie tarcia i nadmiaru danych. Ale im więcej wchodzi prywatności i kryptografii, tym bardziej trzeba pilnować bezpieczeństwa całego modelu.
Bezpieczeństwo, prywatność i odzyskiwanie dostępu
Najczęstszy błąd początkujących polega na założeniu, że decentralizacja sama z siebie rozwiązuje problem bezpieczeństwa. Nie rozwiązuje. Przenosi go tylko w inne miejsce. Jeśli użytkownik traci klucze prywatne, nie ma dobrej strategii odzyskiwania albo źle zarządza portfelem, cały model zaczyna się sypać. W praktyce to właśnie recovery, a nie sama kryptografia, bywa największym wyzwaniem wdrożeniowym.
- Utrata klucza może oznaczać utratę kontroli nad DID, jeśli nie ma sensownego odzyskiwania.
- Linkowalność danych pojawia się wtedy, gdy te same identyfikatory są zbyt łatwe do śledzenia między usługami.
- Niejasna metoda tworzy ryzyko, bo użytkownik nie wie, jakie są zasady aktualizacji i deaktywacji.
- Przeterminowane poświadczenia trzeba umieć unieważniać lub aktualizować.
- Słaby UX portfela potrafi zabić dobry projekt szybciej niż błąd kryptograficzny.
Ważny jest też poziom ujawniania informacji. Dobrze zaprojektowany system nie zmusza do pokazania całej tożsamości przy każdym użyciu. Zamiast tego pozwala odsłonić tylko to, co niezbędne do danej transakcji. To właśnie tutaj DID i poświadczenia dają największą przewagę prywatnościową, choć tylko pod warunkiem, że projekt nie psuje tego własną telemetrią, nadmiarem metadanych albo nieprzemyślanym przechowywaniem historii logowań.
W 2026 patrzę na takie wdrożenia przede wszystkim przez pryzmat zaufania operacyjnego. Nie wystarczy napisać „decentralized” na stronie produktu. Trzeba jeszcze pokazać, kto odpowiada za metodę, jak wygląda recovery, gdzie są punkty awarii i czy użytkownik naprawdę zyskuje kontrolę nad danymi. Dopiero po tej analizie ma sens pytanie, gdzie DID faktycznie daje przewagę biznesową.
Kiedy DID ma sens w biznesie, a kiedy nie
Nie każdy projekt potrzebuje DID. W wielu przypadkach prostsze logowanie przez OAuth, SSO albo klasyczny system kont będzie tańsze, szybsze i po prostu rozsądniejsze. Ja traktuję DID jako odpowiedź na problem zaufania i przenoszalności, a nie jako obowiązkowy element nowoczesnej aplikacji. Jeśli aplikacja ma tylko zarejestrować użytkownika i wysłać newsletter, to nie ma sensu budować wokół tego całej warstwy zdecentralizowanej tożsamości.
| Scenariusz | Czy DID ma sens | Dlaczego |
|---|---|---|
| Weryfikacja dyplomu lub certyfikatu | Tak | Poświadczenie można sprawdzić wielokrotnie bez kontaktu z wystawcą przy każdym użyciu |
| KYC używane w kilku usługach | Tak | Można ograniczyć ponowne zbieranie tych samych danych |
| Członkostwo w społeczności lub DAO | Tak | Liczy się przenośna, weryfikowalna przynależność |
| Prosty login do bloga lub sklepu | Raczej nie | Korzyść jest zbyt mała wobec złożoności wdrożenia |
| System, w którym potrzebny jest szybki time-to-market | Raczej nie | Integracja DID zwykle wydłuża projekt i wymaga dodatkowego utrzymania |
| Ekosystem wielu partnerów biznesowych | Tak | Im więcej weryfikatorów, tym większa wartość interoperacyjnej tożsamości |
Najmocniej DID broni się tam, gdzie użytkownik ma mieć jedną tożsamość użyteczną w wielu miejscach, a firma chce ograniczyć powtarzanie weryfikacji i kopiowanie danych. Słabiej wygląda wtedy, gdy problemem jest tylko wygodne logowanie albo prosty dostęp do jednego serwisu. W praktyce najlepsze wdrożenia są celowane i spokojne, nie próbują zamienić całego internetu w jeden portfel tożsamości. To prowadzi do ostatniego pytania: po czym poznać, że projekt Web3 z DID jest naprawdę dojrzały.
Na co patrzeć, zanim uznasz projekt tożsamości Web3 za dojrzały
Jeśli oceniam rozwiązanie DID, sprawdzam pięć rzeczy. Po pierwsze, czy metoda jest jasno opisana i czy wiadomo, kto nią zarządza. Po drugie, czy istnieje sensowny model odzyskiwania dostępu. Po trzecie, czy poświadczenia są interoperacyjne z innymi narzędziami, a nie zamknięte w jednej aplikacji. Po czwarte, czy system faktycznie ogranicza ujawnianie danych. Po piąte, czy deaktywacja i odwoływanie poświadczeń są zaprojektowane równie dobrze jak samo ich wydawanie.
- Sprawdź, czy metoda DID ma jasne reguły tworzenia, aktualizacji i wygaszania.
- Sprawdź, czy portfel pozwala bezpiecznie odzyskać dostęp po utracie klucza.
- Sprawdź, czy poświadczenia da się zweryfikować poza jednym zamkniętym ekosystemem.
- Sprawdź, czy projekt ogranicza dane, zamiast tylko przenosić je do nowego formatu.
- Sprawdź, czy model działa w praktyce dla użytkownika, a nie tylko na slajdzie produktowym.
W skrócie: DID ma sens wtedy, gdy rozwiązuje konkretny problem zaufania, przenośności albo prywatności. Jeśli projekt nie daje lepszej kontroli nad danymi, nie upraszcza weryfikacji i nie ma sensownego recovery, to najpewniej jest tylko kolejnym eksperymentem z ładnym hasłem. W dobrze zaprojektowanym systemie DID staje się cichą warstwą infrastruktury, a nie celem samym w sobie.